Linux系统漫游(一)从开机到架构
用了好久的 Linux 系统了,然而却没有从头开始好好系统地认识过 Linux,这两篇,就从以下几个方面,漫游式地重新梳理一下关于 Linux 的知识。
本篇:
- Linux简介与版本
- 从开机到启动
- 文件系统
- 文本流
- 标准输入、标准输出、标准错误、重定向
- 管道
- Linux 架构
下一篇:
- 进程
- 进程空间
- 信号
- 进程间通信
- 并发与同步
注:本文提取总结自Vamei的博客
Linux 简介和版本
狭义的 Linux 指的是 Linux kernel (内核),最初由 Linus Torvalds 根据Minix系统的代码,参照UNIX系统的设计写出。kernel 就是负责管理硬件并为上层应用提供接口的底层代码。广义的 Linux 指的是以 Linux kernel 为基础的包括操作系统和各种应用在内的各个Linux版本(distribution)。

上图就是 Linux Kernel 的最初创始人 Linus Torvalds,关于 linus 的介绍,可看Linus,一生只为寻找欢笑,Linus 还出过一本自传《只是为了好玩》,当年在大学图书馆看完这本书心里只有仰望和佩服。
PC平台比较流行的 Linux厂商版本 可以分为两类:
- Redhat系列:包括面向企业的Red Hat Enterprise、由社区维护的Fedora和CentOS等,该系列 Linux版本 的软件安装包以rpm结尾。
- Debian系列:包括完全免费的 Debian 和 继承自 Debian 且界面友好的 Ubuntu ,以及继承自 Ubuntu 但提供了更加丰富的预装应用的Mint,还有预装了许多网络安全、渗透相关工具的kali Linux。 国产做得比较优秀的深度(Deepin)也是属于Debian系列的。这一类 Linux版本 的软件安装包以deb结尾。。
个人用户安装建议
如果只是为了体验一下 Linux 系统,推荐安装有强大的社区支持的 Ubuntu,不想太折腾也可以尝试 Deepin;如果是为了稳定建站等希望有持续的技术支持,但不愿意频繁升级的,可以试试 CentOS ;如果想学习黑客知识、网络安全等,推荐 kali Linux。
此外,还有一些小众的 Linux 发行版就不介绍了。总而言之, Linux 的发行版本非常多。
发一张仅供娱乐的图片。
Linux 开机启动(bootstrap)
注:本小节摘自 Vamei 的博客
最初始阶段
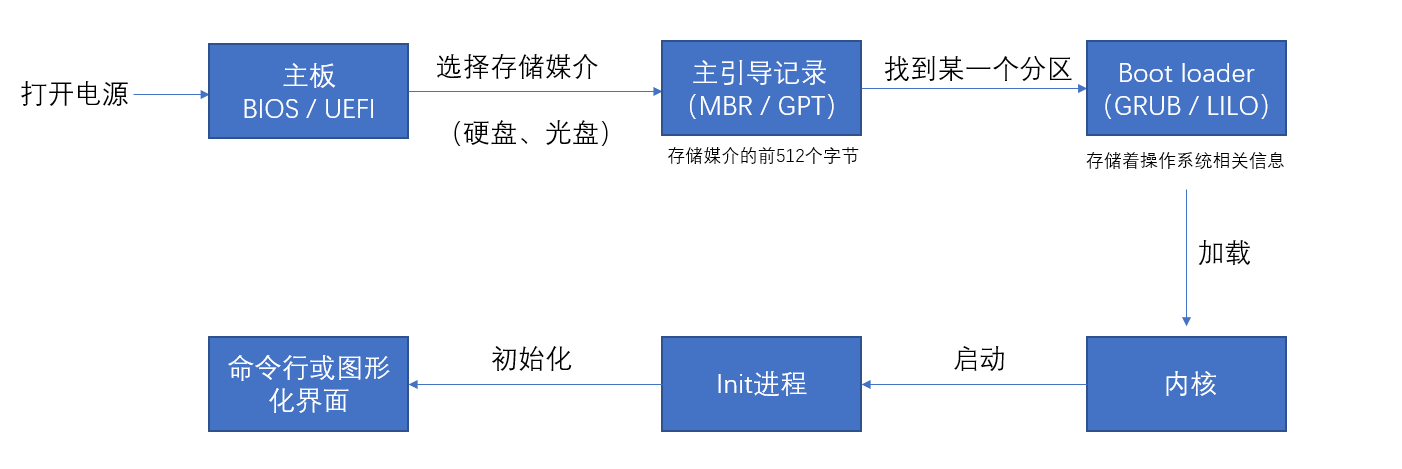
当我们打开计算机电源,计算机会自动从主板的BIOS(Basic Input/Output System)读取其中所存储的程序。这一程序通常知道一些直接连接在主板上的硬件(硬盘,网络接口,键盘,串口,并口)。现在大部分的BIOS允许你从软盘、光盘或者硬盘中选择一个来启动计算机。
随着计算机的发展,传统的BIOS被新的UEFI BIOS替代。UEFI的全称是Unified Extensible Firmware Interface,意即统一可扩展固件接口。UEFI做了很多对传统BIOS的改进。
下一步,计算机将从你所选择的存储设备中读取起始的512个字节(bytes)。如果我们从光盘启动的话,那么计算机就会读取光盘最开始的512个字节。这512个字节叫做 **主引导记录MBR (master boot record)**。MBR会告诉电脑从该设备的某一个分区(partition)来装载 **引导加载程序(boot loader)**。引导加载程序储存有操作系统(OS)的相关信息,比如操作系统名称,操作系统内核所在位置等。常用的引导加载程序有GRUB和LILO。
随着计算机的发展,逐渐出现了GPT来代替MBR。GPT的全称是Globally Unique Identifier Partition Table,意即GUID分区表,它的推出是和UEFI BIOS相辅相成的,鉴于MBR的磁盘容量和分区数量已经不能满足硬件发展的需求,GPT首要的任务就是突破了2.2T分区的限制,最大支持18EB的分区。
随后,引导加载程序会帮助我们加载内核(kernel)。内核实际上是一个用来操作计算机的程序,它是计算机操作系统的内核,主要的任务是管理计算机的硬件资源,充当软件和硬件的接口。操作系统上的任何操作都要通过内核传达给硬件。Windows和Linux各自有自己内核。狭义的操作系统就是指内核,广义的操作系统包括内核以及内核之上的各种应用。
实际上,我们可以在多个分区安装引导加载程序,每个引导加载程序对应不同的操作系统,在读取MBR的时候选择我们想要启动的引导加载程序。这就是多操作系统的原理。
小结:BIOS -> MBR(GPT)-> boot loader -> kernel
内核
如果我们加载的是Linux内核,Linux内核开始工作。内核会首先预留自己运行所需的内存空间,然后通过驱动程序(driver)检测计算机硬件。这样,操作系统就可以知道自己有哪些硬件可用。随后,内核会启动一个init进程。它是Linux系统中的1号进程。到此,内核就完成了在计算机启动阶段的工作,交接给init来管理。
小结: kernel -> init process
init process
(根据boot loader的选项,Linux此时可以进入单用户模式(single user mode)。在此模式下,初始脚本还没有开始执行,我们可以检测并修复计算机可能存在的错误)
随后,init会运行一系列的初始脚本(startup scripts),这些脚本是Linux中常见的shell scripts。这些脚本执行如下功能:
设置计算机名称,时区,检测文件系统,挂载硬盘,清空临时文件,设置网络……
当这些初始脚本加载完毕,操作系统就已经完全准备好了,只是,还没有人可以登录。init会给出登录(login)对话框,或者是图形化的登录界面。
输入用户名(比如说vamei)和密码,DONE!
文件系统
在计算机组成原理中我们知道,内存中的数据会随着掉电而消失。为了关机后还能保存我们的数据,我们需要将数据保存在ROM介质中(光盘、硬盘)。我们把每一份保存的数据称为文件。那么当文件多的时候,我们如何去找到我们需要的文件?这就需要用到文件系统(file system)了。
文件系统是就是文件在逻辑上组织形式,它以一种更加清晰的方式来存放各个文件。Linux 的文件系统本质上是二叉树。要找到一个文件,除了要知道该文件的文件名,还需要知道从树根到该文件的所有目录名。从根目录开始的所有途径的目录名和文件名构成一个路径(path)。
值得注意的是,在Linux系统中,目录也是一种文件。Linux中的文件有目录文件、常规文件、软链接文件三种。对于任意一种文件,我们都可以读取(read),写入(write)和运行(execute),但首先要有相关操作的权限。
上面提到的软链接,可以理解为类似于 Windows 的快捷方式。
文件权限相关可以看另一篇:给自己的 Linux 备忘
文本流
计算机中的数据都是 0 1 这样的二进制,每一个 0 或者 1,称为 **1位(bit)**。Unix 以 字节(byte) 来作为数据的单位,规定每 8 个位,就等于 1 个字节。8 个位,二进制数范围为00000000 - 11111111,对应的十进制数就是 0 - 255
通过ASCII编码,可以把这一个字节转换成为256个字符中的一个。所以,在Unix中,数据完全可以用字符的形式表示出来,也就是所谓的文本(text)。
Unix/Linux的基本哲学之一就是「万物皆文件」(Everything is a file)。前面提到,目录也是一种文件。对于Unix系统来说,文件可以广义的认为是可以提供或接收数据的对象。既然这样,Unix系统干脆把提供或接收数据的硬件也表示成文件。
但 linus 对「万物皆文件」的说法作出过纠正,改为「万物皆文本流」(Everything is a stream of bytes)系统运行时,数据并不是在一个文件里定居。数据会在CPU的指挥下不断地流动。有时数据需要到办公室上班,因此被读入到内存,有时会去酒店休假,传送到外部设备。有的时候,数据需要搬个家,转移到另一个文件。在这样跑来跑去的过程中,数据像是排着队走路的人流,我们叫它 文本流(text stream,或者byte stream)。
然而,计算机不同设备之间的连接方法差异很大,从内存到文件的连接像是爬山,从内存到外设像是游过一条河。为此,Unix定义了流 (stream),作为连接操作系统各处的公路标准。有了“流”,无论是从内存到外设,还是从内存到文件,所有的数据公路都是相同的格式。至于公路下面是石头还是土地,就都交给操作系统处理,不劳用户操心了。
标准输入、标准输出、标准错误
当Unix执行一个程序的时候,会自动打开三个流,标准输入(standard input),标准输出(standard output),标准错误(standard error)。
比如说你打开命令行的时候,默认情况下,命令行的标准输入连接到键盘,标准输出和标准错误都连接到屏幕。对于一个程序来说,尽管它总会打开这三个流,但它会根据需要使用,并不是一定要使用。
想象一下,当我们在 shell 中敲下
ls命令的时候,键盘作为标准输入,把我们敲下的命令文本流传给shell,shell随后调用/bin/ls去解释这个命令,得到结果a.txt,最后这个输出文本流流向标准输出,也就是屏幕,这才显示出来。
如果我们不想让a.txt流向标准输出(屏幕) ,我们可以用>符号来重定向让它流向别的文件,这样目标文件就会被替代成我们输出的结果a.txt。或者,你用>>符号来追加,在原来文件不变的情况下在后面追加我们的a.txt结果。
我们也可以用<符号来改变标准输入。
Linux中,命令 echo 的作用就是将文本流导向标准输出。
管道(pipe)
管道可以将一个命令的输出导向另一个命令的输入,从而让两个(或者更多命令)像流水线一样连续工作,不断地处理文本流。在命令行中,我们用|符号表示管道。
例子:
把 a.txt 作为输入,传给 cat 命令, cat命令解释后的输出通过管道传递给 wc,用于统计字数
1 | cat < a.txt | wc |
Linux 架构
注:本小节摘自 Vamei 的博客
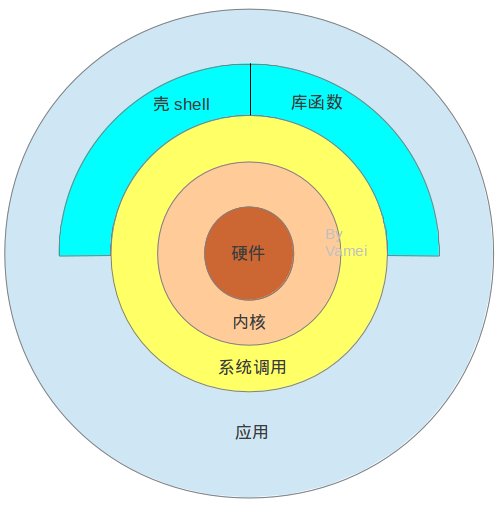
根据上图,我们从内到外,逐一分析!
内核
由上图,硬件是物质基础,而应用提供服务。但在两者之间,还要经过一番周折。Linux首先启动内核 (kernel),内核直接管理管理硬件,包括CPU、内存空间、硬盘接口、网络接口等等。同样,所有的计算机操作都要通过内核传递给硬件。
系统调用
为了方便调用内核,Linux将内核的功能接口制作成系统调用(system call)。系统调用看起来就像C语言的函数。你可以在程序中直接调用。系统调用是操作系统的最小功能单位。
库函数
系统调用提供的功能非常基础,所以使用起来很麻烦。一个简单的给变量分配内存空间的操作,就需要动用多个系统调用。所以,Linux定义一些库函数(library routine)来将系统调用组合成某些常用的功能。
比如,分配内存的操作,可以定义成一个库函数(像malloc()这样的函数)。再比如说,在读取文件的时候,系统调用要求我们设置好所需要的缓冲。我可以使用Standard IO库中的读取函数。这个读取函数既负责设置缓冲,又负责使用读取的系统调用函数。
使用库函数对于机器来说并没有效率上的优势,但可以把程序员从细节中解救出来。
shell
那么跟库函数处于同等地位的 shell 又是何方神圣呢?
shell是一个特殊的应用。很多用户将它称为命令行。shell是一个命令解释器(interpreter),当我们输入“ls -l”的时候,它将此字符串解释为
- 在默认路径找到该文件(/bin/ls),
- 执行该文件,并附带参数”-l”。
shell是可编程的,它可以执行符合shell语法的文本。这样的文本叫做shell脚本(script)。
UNIX的一条哲学是让每个程序尽量独立的做好一个小的功能。而shell充当了这些小功能之间的”胶水”,让不同程序能够以一个清晰的接口(文本流)协同工作,从而增强各个程序的功能。这也是Linux老鸟鼓励新手多用shell,少用图形化界面的原因之一。
应用
最后,我们进入一般的应用。应用是一个程序,它可以
- 直接调用系统函数
- 调用库函数
- 运行shell脚本
这些应用可以由多种语言开发。最常见的是C语言。
由于篇幅原因,这一篇先介绍到这里,下一篇继续介绍进程、信号、并发等知识。