1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
|
import os
import requests
from lxml import etree
from PIL import Image
from bs4 import BeautifulSoup
import urllib.parse
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Host": "jwgl.zsc.edu.cn:90",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Upgrade-Insecure-Requests": "1"
}
headers_code = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Host": "jwgl.zsc.edu.cn:90",
"Cache-Control": "max-age=0"
}
grade_headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Host": "jwgl.zsc.edu.cn:90",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Upgrade-Insecure-Requests": "1"
}
def login_jcgl(session):
global number
number = input('请输入学号:')
password = input("请输入密码:")
url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx"
response = session.get(url)
cookies = requests.utils.dict_from_cookiejar(s.cookies)
headers.update(cookies)
headers_code.update(cookies)
check_code_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/CheckCode.aspx"
pic_response = session.get(check_code_url, headers=headers_code).content
with open('ver_pic.jpg', 'wb') as f:
f.write(pic_response)
image = Image.open('{}\\ver_pic.jpg'.format(os.getcwd()))
image.show()
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="form1"]/input/@value')[0]
data = {
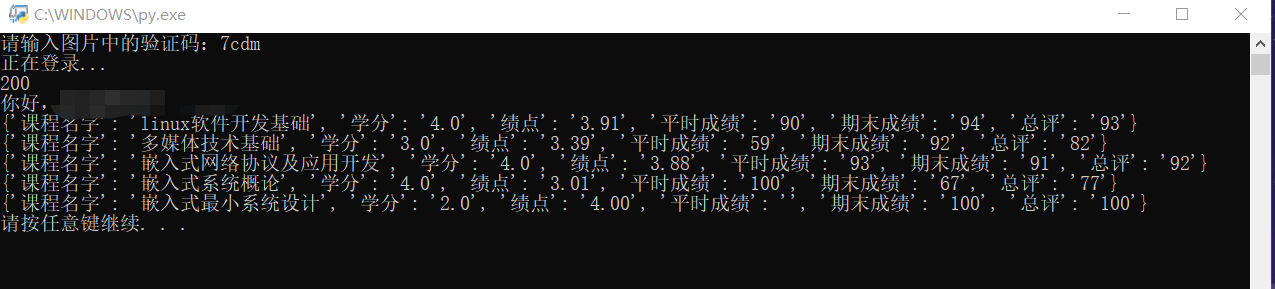
'txtSecretCode': str(input('请输入图片中的验证码:')),
'txtUserName': str(number),
'Textbox1': '',
'TextBox2': str(password),
'__VIEWSTATE': __VIEWSTATE,
'RadioButtonList1': u"学生".encode('gb2312', 'replace'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': ''
}
response = s.post(url, data=data, headers=headers)
print("正在登录...")
print(response.status_code)
if "验证码不正确" in response.text:
print("验证码不正确")
return login_jcgl(s)
if ("密码错误" or "密码不能为空") in response.text:
print("密码错误")
return login_jcgl(s)
if ("用户名不能为空" or "用户名不存在或未按照要求参加教学活动") in response.text:
print("学号错误")
return login_jcgl(s)
else:
print("登录成功!")
global student
student = getInfor(response, '//*[@id="xhxm"]/text()').replace("同学", "")
print("你好," + student + " " + number)
return response
def getInfor(response, xpath):
content = response.content.decode('gb2312')
selector = etree.HTML(content)
infor = selector.xpath(xpath)[0]
return infor
def login_grade(session):
student_name = urllib.parse.quote(student.encode("gb2312"))
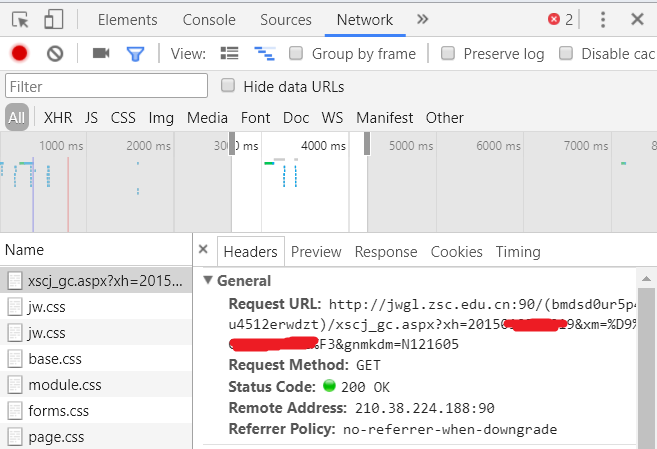
grade_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/xscj_gc.aspx?xh={}&xm={}&gnmkdm=N121605".format(number, student_name)
cookies = requests.utils.dict_from_cookiejar(s.cookies)
grade_headers.update(cookies)
response = session.get(grade_url, headers=grade_headers)
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="Form1"]/input/@value')[0]
data = {
"__VIEWSTATE": __VIEWSTATE,
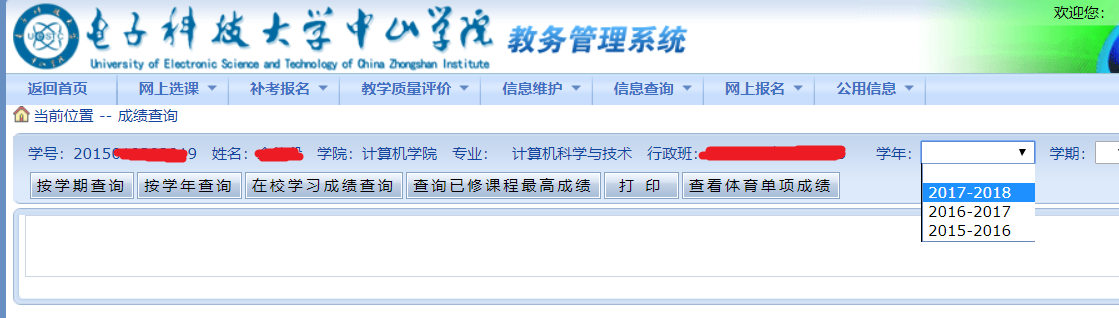
"ddlXN": "2017-2018",
"ddlXQ": 1,
"Button5": u"按学年查询".encode('gb2312', 'replace'),
}
response = s.post(grade_url, headers=grade_headers, data=data)
return response
def getGrade(response):
html = response.content.decode("gb2312")
soup = BeautifulSoup(html, "html5lib")
trs = soup.find(id="Datagrid1").findAll("tr")[1:]
Grades = []
for tr in trs:
tds = tr.findAll("td")
tds = tds[3:4] + tds[6:9] + tds[10:13:2]
oneGradeKeys = ["课程名字", "学分", "绩点", "平时成绩", "期末成绩", "总评"]
oneGradeValues = []
for td in tds:
s = td.string.replace(" ", "")
s = "".join(s.split())
oneGradeValues.append(s)
oneGrade = dict((key, value) for key, value in zip(oneGradeKeys, oneGradeValues))
Grades.append(oneGrade)
return Grades
s = requests.Session()
response = login_jcgl(s)
response = login_grade(s)
result = getGrade(response)
for go in result:
print(go)
os.system("pause")
|